The DNS server was unable to open Active Directory”
Recently , One of our customer reported an issue stating that the Exchange Services are failing and Outlook clients are getting disconnected. We noticed few DC related events (Kerberos) on both the exchange servers. Thus , we ran the “netdom query fsmo” command on the 2 Exchange Servers and got the below error:
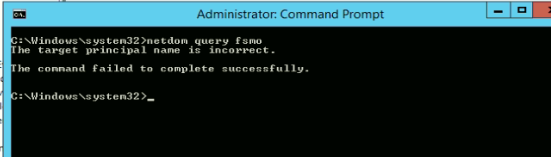
The same error appeared on all the other domain joined servers. Therefore ,we decided to check the DC’s.
When we reviewed the event viewer on the 2 DC’s , there were DNS related errors(Event ID 4000)

Further , we could not open the DNS MMC snap-ins and pinging the hostname by DC was failing as well. However, the DNS service is started state. In addition to this , there were errors on KDC consistency as well. After , troubleshooting for few minutes ,we go hold of the Microsoft KB :https://docs.microsoft.com/en-us/troubleshoot/windows-server/networking/dns-zones-do-not-load-event-4000-4007 and followed the steps mentioned to resolve the issue successfully.
Few points to consider:
– You will find an additional “d: in the word password in the below command. Do not change it.
netdom resetpwd /server: /userd: netdom resetpwd /server: /userd: /passwordd:*
– In my case I had to run this command on the PDC and the other DC as well
– Stop the KDC service prior to running the command.
– First I started on the PDC and restarted it and ensured the DNS snap-in was accessible and the pinging
by hostname was working.
– Finally , I continued the same steps on the remaining domain controllers.
After updating vCSA to 6.7 U2 or higher, unable to log into the VAMI page- “Invalid Credentials” or “Unable to Login”
We recently had a situation , where we were not able to login to VAMI Page of the VCSA . As it was continuously providing the unable to login error. However , we know that the password is correct.
When we logged in to the SSH of the VCSA , we noticed that the applmgmt service is not started. We had to manually start it. Then the login to the VAMI got restored. However , when the appliance is rebooted the same issues pops up again. So ,we followed the VMware KB #68149(https://kb.vmware.com/s/article/68149) , but no success.
Finally , we decided to contact the VMware support and the resolution was very quick . It was due to sqlite DB used by the vmware-statsmonitor serivce(In our case , when we reboot the VCSA both the statsmonitor & applmgemt services were not coming up). The DB was reaching around 500 MB in size. The resolution was simple , he moved the DB file to a temporary location and restarted the vmware-statsmonitor service. We noticed a new appliance_stats.sqlite file got created in the same path /var/vmware/applmgmt/.
The DB file is located in /var/vmware/applmgmt/appliance_stats.sqlite.
We rebooted the VCSA and confirmed that we can login to the VAMI successfully.
Please note that this process will remove the previous stats collected on the VCSA.
Good luck.
How to check the AD Schema version
We all know , how to check the FFL & DFL version using the AD Snap-ins.However , if you want to check the AD schema version , you need to run regsvr32 schmmgmt.dll to active the MMC snap-in to get the required details.
Most of the time this process will fail and need additional troubleshooting steps. Instead of that , you can use the below PowerShell command to easily get the AD schema version. In the meantime , you could still use the ADSI Edit as well.
Get-ADObject (Get-ADRootDSE).schemaNamingContext -Property objectVersion
Output of the above command will give you a value for the ObjectVersion. This value need to be compared with below to obtain the correct schema version.

Source: https://support.globalsign.com/aeg/aeg-how-check-active-directory-schema-version
How to use KMS based activation for Windows images
Hi All
In our Hosting environment , we had to deploy large number of Windows Servers. We need to ensure that the Windows images are remain active within our datacenters only. As we cannot use MAK based activation. Because , if the customer moves out from us the licenses should be not active . In other words , it is customer responsibility to reactivate the Windows in his new environment.
So we came up with the idea of KMS based activation using VMware Templates and this is how we did it.
- Install the KMS Service on a Windows 2019 and activate it with the KMS Key.
( I am not writing the steps here .Since a simple Google search result will yield lot’s how-to articles on KMS installation.) - Created a Windows 2019 VM.
- Activated the Windows 2019 with the GVLK. You can refer the below URL for the GVLK keys.
https://docs.microsoft.com/en-us/windows-server/get-started/kmsclientkeys - Ran the Sysprep and converted it to a template.
- Thereafter , we created a custom specification file to perform the KMS activation on Windows image. All these settings are mandatory .Otherwise , the KMS commands will fail to run.
+ In the Windows License Page , clear all the settings.

+ In the Administrator Password and set a Password ,
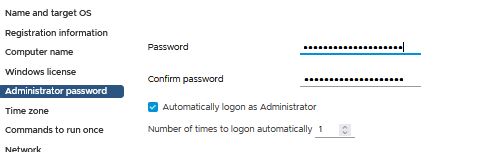
+ In the Commands to run once Page, enter the below commands
cscript c:\windows\system32\slmgr.vbs /skms “kms server ip”:1688
cscript c:\windows\system32\slmgr.vbs /ato

That’s it. Now you can go ahead and deploy the Windows images and get it activated by KMS.
Further reading:
1)Use the below command on your Windows images to verify the CMID(Client Machine ID is not duplicated).
Get-WmiObject -class SoftwareLicensingService | Select-object ClientMachineID
Duplicated CMID will prevent VM’s from getting activated.
2) On the KMS client you can review the below Registry key to verify the correct KMS settings have been applied.
HKLM/SOFTWARE/MICROSOFT/WINDOWSNT/CURRENTVERSION/SOFTWAREPROTECTIONPLATFORM/
–KeyManagementServiceName
–KeyManagementServicePort
3) Use the below commands on the KMS Server & Clients to verify the Windows Activation.
slmgr /dlv
slmgr /dli
How to renew vSphere 6.5 & 6.7 certificates.
When the VCenter Certificate is expired , you will be blocked from logging in to the VCenter . However , the Appliance Management will continue to work. Be noted that there a 2 categories of certificates.
- VMware Security Token Service (STS)
- Solution , Machine , Root and Other certificates.
Import Notes:
- You could avoid all these messy steps , had you monitor and check for the
warnings on the VCenter Administration page for Certificate expiry events. - For Windows based VCenter , you can refer the same KB’s mentioned here for the detailed steps.
- You may face an error when uploading the scripts to the VCSA via WinSCP . The Solution is provided in the same KB’s.
- Certificate Manager may fail during the process , you could refer the https://mueller-tech.com/2019/06/28/replacing-expired-certificates/ for the solution.
I used the below mentioned steps to confirm the expiry date for both of these certificates
STS – Please refer the KB:
https://kb.vmware.com/s/article/79248 (It will require to download a script – checksts.py)
Others – Run the below command in the VCSA.
for i in $(/usr/lib/vmware-vmafd/bin/vecs-cli store list); do echo STORE $i; sudo /usr/lib/vmware-vmafd/bin/vecs-cli entry list –store $i –text | egrep “Alias|Not After”; done
In my situation , both of the certificate types were expired and I had to replace all of them. To replace the STS certifcate , you could utilize a script provided by VMWare (fixsts.sh) using the KB : https://kb.vmware.com/s/article/76719
Once it is done , you need to restart the VCenter services using the below commands.
service-control –stop –all
service-control –start –all
service-control –status.
Thereafter , you could proceed to replace the other certificates using the VSphere Certificate Manager https://kb.vmware.com/s/article/2112283
How to verify SPF/DKIM/DMARC/DomainKey/RBL tests parsed on the email.
Hi All
In some situations , when an email is blocked by the antispam device , you need to analyze the headers to findout the actual root cause. However , sometimes the blocked reasons shown by the antispam device are not descriptive especially when you are troubleshooting DKIM related failures.
This is crucial as we need notify the sender’s domain owner to rectify the issues. In these cases you could use the below tool to analyze the tests performed in the email and findout the actual reason for the email blockage in a much descriptive manner.
https://www.appmaildev.com/en/dkimfile
I found it very useful , and thought of sharing it with the community.
Good luck guys.
DCPromo Fails – The directory service is missing mandatory configuration information
Last week , we worked on a AD migration project. This project involved deploying a Windows 2016 based Domain Controller and then decommission the Windows 2008R2 domain controller.
We successfully transferred the FSMO roles . During the decommissioning process when we ran the dcpromo command we received the error “The directory service is missing mandatory configuration information”
During the troubleshooting the MS KB (https://docs.microsoft.com/en-us/troubleshoot/windows-server/identity/dcpromo-demotion-fails) was pointing us to correct direction. The issue was related to fsmoroleowner attribute on CN=Infrastructure is not set properly. In my case it was pointing to the server which I am trying to demote.
You can see this by opening ADSI Edit;
Right click the ADSI Edit root and click on Connect to…
Use the following connection point: DC=DomainDNSZones,DC=abc,DC=local (Replace it with your actual AD DNS Zone)
Click on Default Naming Context [DC.abc.local] to populate it.
Click on DC=DomainDNSZones,DC=abc,DC=local folder.
Double click on CN=Infrastructure.
Locate the fSMORoleOwner attribute
Ensure you connect to DC=ForestDNSZones as well to verify the attribute.
In my case DomainZones was showing the correct DC .But the ForestDNSZones pointing to the Windows 2008R2 Server.
I have tried the manual method using the ADSI Edit to change the value. However it was failing with the error “The role owner attribute could not be read”
In this case you need to refer the MS KB https://docs.microsoft.com/en-us/troubleshoot/windows-server/identity/dcpromo-demotion-fails to create the .vbs file to fix this issue.( I have seen suggestions to run the dcpromo /forceremoval instead and then run a metadata cleanup. I do not recommend this approach)
The script provided in the KB does not work due to incorrect end statements. Luckily the Blogger veducate.co.uk (https://veducate.co.uk/dcpromo-fails-missing-mandatory-configuration/) have provided a fixed version.
NOTE: You need to run these commands from the current owner of the FSMO roles.
Create a .vbs file via CMD
fsutil file createnew fixfsmo.vbs 0
Copy the below contents to the file
================================================
const ADS_NAME_INITTYPE_GC = 3
const ADS_NAME_TYPE_1779 = 1
const ADS_NAME_TYPE_CANONICAL = 2
set inArgs = WScript.Arguments
if (inArgs.Count = 1) then
‘ Assume the command line argument is the NDNC (in DN form) to use.
NdncDN = inArgs(0)
Else
Wscript.StdOut.Write “usage: cscript fixfsmo.vbs NdncDN”
End if
if (NdncDN <> “”) then
‘ Convert the DN form of the NDNC into DNS dotted form.
Set objTranslator = CreateObject(“NameTranslate”)
objTranslator.Init ADS_NAME_INITTYPE_GC, “”
objTranslator.Set ADS_NAME_TYPE_1779, NdncDN
strDomainDNS = objTranslator.Get(ADS_NAME_TYPE_CANONICAL)
strDomainDNS = Left(strDomainDNS, len(strDomainDNS)-1)
Wscript.Echo “DNS name: ” & strDomainDNS
‘ Find a domain controller that hosts this NDNC and that is online.
set objRootDSE = GetObject(“LDAP://” & strDomainDNS & “/RootDSE”)
strDnsHostName = objRootDSE.Get(“dnsHostName”)
strDsServiceName = objRootDSE.Get(“dsServiceName”)
Wscript.Echo “Using DC ” & strDnsHostName
‘ Get the current infrastructure fsmo.
strInfraDN = “CN=Infrastructure,” & NdncDN
set objInfra = GetObject(“LDAP://” & strInfraDN)
Wscript.Echo “infra fsmo is ” & objInfra.fsmoroleowner
‘ If the current fsmo holder is deleted, set the fsmo holder to this domain controller.
if (InStr(objInfra.fsmoroleowner, “\0ADEL:”) > 0) then
‘ Set the fsmo holder to this domain controller.
objInfra.Put “fSMORoleOwner”, strDsServiceName
objInfra.SetInfo
‘ Read the fsmo holder back.
set objInfra = GetObject(“LDAP://” & strInfraDN)
Wscript.Echo “infra fsmo changed to:” & objInfra.fsmoroleowner
End if
End if
=================================================
Run the file twice as below
1) cscript fixfsmo.vbs dc=forestdnszones,dc=abc,dc=local
2) cscript fixfsmo.vbs dc=domaindnszones,dc=abc,dc=local
Voila , The fsmoroleowner attribute got updated with the correct server name , and I was able to demote the server successfully.
Source: (Helped me to fix the syntax errors on script provided by Microsoft)
DCPromo Fails – The directory service is missing mandatory configuration information
Thanks.
How to create a Ubuntu 18.04.5 template in VSphere ESXi 6.7
As usual you need to create a VM and install Ubuntu in to it. Thereafter you need to follow the below steps to strip out the unique data being propagated to the VM’s you create from the template.
+Update the OS
#sudo apt -y update
#sudo apt -y upgrade
+Clear audit logs
truncate -s0 /var/log/wtmp
truncate -s0 /var/log/lastlog
+Clear the tmp
#rm -rf /tmp/*
rm -rf /var/tmp/*
+Clear the SSH
#rm -f /etc/ssh/ssh_host_*
+Reset the hostname
#sed -i ‘s/preserve_hostname: false/preserve_hostname: true/g’ /etc/cloud/cloud.cfg
#truncate -s0 /etc/hostname
#hostnamectl set-hostname localhost
+Clean apt
#apt clean
+Remove the default *.yaml file from the /etc/netplan. The VMware customizaion will create it’s own file 99-netcfg-vmware.yaml.
#rm -f /etc/netplan/*.yaml
+Reset the machine id
#echo -n > /etc/machine-id
+Clear the history & shutdown the VM
#history -c
#shutdown -h now
On the vCenter you need to create a VM Customization specification to be used when deploying the VM’s from the template(Refer:How to create a RHEL 7 template in VSphere ESXi 6.7 for steps).
However , when I created the VM’s from this template I realised that
- All the VM’s are having the same hostid. Some applications uses the hostid in their licensing .Thus, it has to be unique across the VM’s. Since I did not find a way to solve this while deploying the VM’, I had to do a manual modification as mentioned below on the VM’s after it being created.
#vi /etc/hosts
replace the line “127.0.1.1 localhost” with
your IP FQDN Hostname (E.g: 1.1.1.1 server.test.local server). - You need to manually select the “Connected” option in The VM network Adapter in the VM properties.
The Microsoft Exchange Replication service couldn’t find a valid configuration for database ‘mydb’ on server ‘server1’. Error: An Active Manager operation failed. Error: The active copy for database could not be determined:
Recently one of our customer had an Exchange Server outage. Whereas one of the node from 2 node DAG was not able to communicate with other server. We tried to rebooting the server but no luck . The symptoms were
– Cluster service was not starting.
– On the other node FCM was not able to connect to the DAG cluster.
– Unable to open the ECP/OWA.
– Outlook / Mobile Users cannot access their mailboxes.
The environment consist of 2 Exchange Server 2016 & DAG.
So we started with removing the failed node by typing the below commands in the healthy exchange server:
# Open Exchange PowerShell
#Get-ClusterNode -Name node1 | Remove-Clusternode
# net stop clussvc
# net start clussvc
# Remove-DatabaseAvailabilityGroupServer -Identity “DAG Name” -MailboxServer “Failed Exchange Server Name” -ConfigurationOnly
# Get-ClusterNode “Failed Exchange Server Name” | Remove-ClusterNode
However , still no luck. Then we tried to remove the mailbox database copies form the failed node(I believe the copies were active on the second server) we got a new error stating that “Mailbox databse copies cannot be disabled on the Databases with circular logging enabled. So we had to remove the circular logging and then delete the database copies.
#Get-MailboxDatabse | Set-MailboxDatabase -CircularLoggingEnabled $False
# Get-MailboxDatabaseCopy -Identity “DatabaseName” |Remove-MailboxDatabaseCopy -Identity “DatabaseName\ServerName”
Now it is the time for mounting the databses: When we ran the below command
#Get-MailboxDatabase | Mount-Database
We received the below error”
Failed to mount database “———-“. Error: An Active Manager operation failed. Error: An Active Manager operation
encountered an error. To perform this operation, the server must be a member of a database availability group, and the
database availability group must have quorum. Error: Automount consensus not reached (Reason: FSW boot time did not
match (FSW-Remote: 2020-10-01T11:37:09.4930830Z FSW-Reg: 0001-01-01T00:00:00.0000000)). [Server:———-]
+ CategoryInfo : InvalidOperation: (—-:ADObjectId) [Mount-Database], InvalidOperationException
+ FullyQualifiedErrorId : [Server=————,RequestId=5022acdd-0c48-4584-b2eb-1d0a2c692f0d,TimeStamp=10/7/2020
11:09:14 AM] [FailureCategory=Cmdlet-InvalidOperationException] BCF4F25E,Microsoft.Exchange.Management.SystemConfi
gurationTasks.MountDatabase
Here , we wanted to check the DAG status
#Get-DatabaseAvailabilityGroup -status
Output :
WARNING: Unable to get Primary Active Manager information due to an Active Manager call failure. Error: An Active
Manager operation failed. Error: An Active Manager operation encountered an error. To perform this operation, the
server must be a member of a database availability group, and the database availability group must have quorum. Error:
Automount consensus not reached (Reason: FSW boot time did not match (FSW-Remote: 2020-10-01T11:37:09.4930830Z FSW-Reg:
0001-01-01T00:00:00.0000000)). [Server: ———-]
Name : DAGName
Memberservers: {Server1}
Operational Servers {}
The output confirmed that there a no operatinal servers. So we had to restart the DAG with the surviving node.
#Start-DatabaseAvailabilityGroup -Identity “DAGNAME” -MailboxServer ServerName”
Now the Get-DatabaseAvailabilityGroup -status cmd will gave the below output:
Name : DAGName
Memberservers: {Server1}
Operational Servers {Server1}
Now it is the time for mounting all the databases:
Get-MailboxDatabase | Mount-Database
Voila , The MailboxDatabases were started mounting and the ECP access is restored.
Free Radius : Auth: (0) Invalid user (Rejected: User-Name contains multiple ..s): [xxx]
Recently we performed a Yum update on our Free Radius Server. The newer version is FreeRADIUS Version 3.0.13. At that time , we started receiving complains from the users that they are not able to login to the network devices.
After reviewing the logs , we noticed the error “Auth: (0) Invalid user (Rejected: User-Name contains multiple ..s)” being logged during the authentication. This is due to the changes applied in the filter file(/etc/raddb/policy.d/filter ).
Before Update:
if (&User-Name =~ /\\.\\./ ) {
After Update:
if (&User-Name =~ /\.\./ ) {
The new Regex syntax style doesn’t escape backslashes anymore. So you need to ensure that the correct_escapes = true property is set in /etc/raddb/radiusd.conf.
